
At first, MTTR in cybersecurity gauges how fast firms recover from cyber incidents. A lower MTTR reduces downtime, costs, and risks, while AI-driven tools boost detection, response, and overall cyber resilience.
Quick Overview of MTTR’s Critical Role:
- Purposeful Incident Recovery: MTTR is one of the key measures in determining the efficacy of an organization in responding to a cybersecurity incident, especially in the time frame between the discovery of the threat and restoring operations.
- Critical Enabler of Cyber Resilience: A low MTTR is important because it means that any downtime is limited in time, financial impact is reduced, regulatory compliance is improved, and trust with participants is strengthened, leading to overall improved cyber resilience.
- The use of engaging technology, including AI-enabled monitoring, automation, and visibility tools, modernizes incident response efforts and introduces new capabilities to reduce detection and remediation times.
In today’s digital environment, the argument that cyberattacks are not only a likelihood but a certainty has come to be an elemental reality. Organizations in all industries are subjected to a constant influx of ever-refined threats; hence, the tempo and effectiveness of recovery from them are a determining factor in maintaining continuous operations and protecting digital assets.
At its core, the critical assessment and improvement of this key ability involves a measurement known as Mean Time to Repair (MTTR). This in-depth study will clarify the meaning of MTTR, explain its deeper meaning in terms of a cybersecurity context, show how to calculate it, survey its various usage across IT disciplines, and provide tactical mechanisms for reducing it, so that technology professionals and students will have applicable knowledge to facilitate hardening within their organizations.
What is MTTR? Defining the Pillars of Recovery
MTTR is a key metric representing the average time required to restore a system, service, or component to normal operations after a disturbance or incident. While MTTR is usually defined as Mean Time to Repair, it frequently covers a set of closely related concepts, including:
- Mean Time to Respond: The speed of action taken to initially detect and contain an incident by an organization.
- Mean Time to Recover: The time taken to get affected systems or services back up and normal operations restored.
- Mean Time to Resolve: This more expansive definition encompasses the entire lifecycle, from incident detection to incident closure, including root cause analysis and follow-up preventive actions.
With regard to the cybersecurity discipline, MTTR encompasses the lifecycle from the initial detection of a security incident or security weakness/vulnerability to restoring the secured/ remediated conditions of systems in a validated state. MTTR is an input metric used to assess an organization’s incident response and recovery capabilities, ultimately driving improvements to operational continuity and risk mitigation processes.
MTTR in Cybersecurity: Why Its Speed is Paramount?
The importance of MTTR in cybersecurity cannot be overstated. It is a vital component of strong security governance frameworks and has a direct impact on an organization’s capability to survive and recover from a malicious attack. MTTR has importance due to many important factors:
- Faster Detection and Response: A lower MTTR means that an organization can identify and contain security incidents more quickly, which reduces an attacker’s dwell time—the time that an attacker ‘hides’ in a system before being detected—cutting down any potential damage or data theft, and reducing an attack’s blast radius.
- Faster Recovery from Incidents: A lower MTTR indicates that normal operations can be restored faster. This allows for less harmful downtime and reduced productivity losses. It increases the likelihood of business continuity, where revenue, services, and other critical operational components stay intact.
- Regulatory Obligations: Many regulations and standards, both globally and regionally (e.g., GDPR, HIPAA, PCI DSS), contain strict timelines that require organizations to respond to incidents and provide notifications. Capable metrics for MTTR can help organizations prove compliance with these frameworks and lessen the negative effects of costly fines/legal penalties.
- Uptime and Service Availability: Integrated with service availability is the ongoing improvement of MTTR lag. A low MTTR means the system is reliable, and users trust the service. Conversely, a high MTTR metric erodes user confidence and leads to reputational loss.
MTTR represents an organization’s ability to respond to incidents and mitigate the exposure and impacts of cyber events, making it an essential part of a proactive cybersecurity capability.
The MTTR Formula: Quantifying Resolution Efficiency
MTTR provides a quantifiable measure of an organization’s efficiency in resolving incidents. The fundamental formula for calculating MTTR is both straightforward and powerful:
MTTR = Total Downtime / Number of Incidents
Consider an example: If an organization experiences 4 cybersecurity incidents within a given period, leading to a cumulative downtime of 24 hours, the MTTR would be calculated as follows:
MTTR = 24 hours / 4 = 6 hours
This calculation indicates that, on average, the organization requires 6 hours to restore systems and resolve issues after a cybersecurity incident. This provides a clear baseline for performance assessment and improvement initiatives.
Key Metrics: A Broader Perspective on Incident Response
Whereas MTTR gives an overall view of resolution efficiency, it’s essential to view it alongside other important measurements that get even more granular into the incident response lifecycle:
Response Time
Response time is defined as the elapsed time from the initial notification of an incident until the start of the first action responding to the incident. It captures how quickly the organization acknowledges the incident and what immediate steps are taken to contain or remediate the threat, and it will often be a subset of MTTR.
Recovery Time
Recovery time is the time it takes to restore systems or services to their normal operational state after the event has taken place. It is an important metric for disaster recovery and business continuity plans.
MTTD vs. MTTR: The Detection-to-Resolution Spectrum
The biggest difference is between Mean Time to Detect (MTTD) and MTTR. MTTD measures how long it takes from the actual occurrence of an incident until it is discovered. On the other hand, MTTR measures the elapsed time from the detection of the incident to when the incident has been completely resolved.
As a low MTTD is fundamental to a low MTTR, an incident cannot be remediated until it has been detected. Taken together, these measurements provide a comprehensive view of an organization’s security operations, from initial awareness of a threat through to resolution.
Cross-Domain Utility: MTTR Across IT and Security Functions
The applicability of MTTR goes far beyond pure cybersecurity and is a useful metric in almost every aspect of IT, due simply to its focus on organizational processes and operational effectiveness with respect to system uptime:
Incident Management

In incident management, MTTR is a fundamental standard for the effectiveness of incident response processes, as it enables teams to identify bottlenecks, refine workflows, and enhance incident playbooks and other processes. Thus, driving continued to be a gradual process.
DevOps

In a continuous integration and continuous delivery (CI/CD) environment, MTTR is important for supporting the ongoing movement of pipelines. It provides a means to quickly rectify errors, build confidence in rollback strategies, and address security vulnerabilities after deployment, aligning with the principles of agile development.
Cloud Computing

When considering cloud computing’s distributed nature and ongoing management of service disruptions, MTTR can be used to measure the resilience of cloud-native architectures, while identifying the effectiveness of automated failover procedures, to ensure high availability for operations, especially in complex multi-cloud or hybrid environments.
Networking

Network reliability is often directly tied to a reduction in MTTR. The metric, when used by an incident or network administrator, provides a numerical value that indicates how effectively that person can mitigate an outage, degradation of performance, or security breach that affects incoming and outgoing network performance and throughput. The goal is for users to have access to network resources where, from the network perspective, continuously receiving data or information is unimpeded.
Maintenance

In both IT and operational technology (OT) contexts, MTTR in maintenance refers to the average time required to repair a piece of equipment or system failure. It informs proactive maintenance schedules and assists teams in optimizing downtime, thus increasing asset uptime and operational effectiveness.
Strategies for Improving MTTR: Cultivating Rapid Recovery
Finding ways to cut MTTR should involve a well-thought-out, multi-pronged approach, taking into account optimization of processes, implementation of technology, and a commitment to ongoing training of personnel. Some common strategies include:
- Improving Monitoring and Alerting Systems: Setting up dedicated, real-time monitoring systems with full visibility across all layers of the full stack (applications, infrastructure, and network) helps organizations identify incidents quickly and diagnose them as fast as possible. Tuning alerts and suppressing those that create noise (false positives) is crucial for quickly identifying critical incidents.
- Efficient Incident Response Actions: Developing and evolving incident response plans and runbooks allows organizations to recognize effective and repeatable actions that are easy to adopt. Everyone involved in the incident response process should understand their roles, the resources and tools available, and should always have a channel of communication established, even in the midst of chaos.
- Training and Re-Training Staff: Organizations must continuously train their security and IT personnel through the use of tabletop exercises and simulated incidents to ensure ongoing preparedness. Continuous training not only prepares staff members to diagnose and resolve failures/bugs, but it also refines the staff’s mindset, keeping them sharp and aware of all types of incidents.
- Building Redundant, Automated Failover: Building redundant systems and creating system architectures that fail over automatically reduces your recovery time objective (RTO) to zero, as an outage will typically be remedied immediately, as the operations of users, customers, and internal staff will be using multiple backup systems throughout the outage period.
- Coordinating Across Teams: Security, operations, development, and business teams must communicate and coordinate effectively to ensure seamless collaboration and integration. Incident response should involve all sustainability groups working together towards a shared goal to quickly resume service activity.
- Geraldine Proactive Vulnerability Management: Regularly identifying, assessing, and prioritizing vulnerabilities via rigorous vulnerability scanning and penetration testing, and using a solid patch management process, will, in many cases, prevent incidents from occurring in the first place and will also have an impact on MTTR if it lowers the number of incidents.
These activities aim to reduce the time period between issue detection and resolution, thereby strengthening the overall security posture.
Empowering Rapid Response: Tools and AI Solutions
Technological advancements, especially in artificial intelligence and automation, have fundamentally changed the ability of organizations to decrease MTTR and provided unprecedented capabilities for detection, assessment, and remediating:
- Incident Response (IR) Platforms – Also known as dedicated IR platforms, take full advantage of the end-to-end incident management life cycle, from detection and investigation through to remediating and reporting. Armed with a central command console, teams gain improved visibility and control over relatively high-impact response activities and associated team actions.
- AI-Powered Monitoring and Observability – Artificial intelligence and machine learning algorithms can comb through massive amounts of data from logs, metrics, and traces to detect anomalies, detect potential threats in real-time, and anticipate future threats. It reduces the time it takes to detect a threat and provides various contexts to optimize real-time diagnosis. Comprehensive observability suites also enable end-to-end visibility across distributed systems, allowing quick identification of where something is failing.
- Automation and Orchestration Tools (SOAR) – Security Orchestration, Automation, and Response (SOAR) establishes a workflow to automate repetitive and mundane tasks, such as initial diagnostics, threat containment, and threat data enrichment. By focusing Human Analysts on complex and high-value responsibilities, there will be shorter distances to complacency, speed up response workflows, and ensure that responses are executed consistently.
- AI Agents: New AI agents and intelligent assistants can aid with incident triage, recommend remediation for past issues, and even be proactive to remediate selected vulnerabilities or system misconfigurations if programmed to do so. This capability further reduces MTTR by lessening the need for manual effort and human decision-making about repetitive incidents.
The thoughtful adoption of these technologies is essential for modern cybersecurity operations, enabling organizations to transition from reactive incident management to proactive and predictive incident management.
Strategic Imperative: Why Lowering MTTR Matters?
Reducing MTTR is not only a technical goal but a strategic necessity that provides meaningful advantages to the business and increases the overall resiliency of the organization:
- Reduces Exposure: A reduced MTTR directly reduces the amount of time when attackers can exploit access to the compromised system, steal sensitive data, or achieve widespread damage. Reducing time in this window reduces the impact and scope of the breach.
- Protects Organizational Reputation and Customer Trust: Reacting quickly to incidents and minimizing any service disruptions protects the organization’s reputation. When an organization demonstrates that it is quick and reliable in its response process, it maintains customer trust in the organization, as well as in its partners and stakeholders, while also emphasizing the organization’s commitment to security.
- Helps with Regulatory Compliance and Governance: Providing regulators with an effective capability for responding to incidents assists in compliance with strict data protection regulations and industry standards. In turn, this reduces the concern about non-compliance and lends more credibility to the organization’s governance posture.
- Reduces Financial Exposure: The faster you recover, the lower the incident timeframe is (downtime), which, in turn, minimizes the total amount of lost revenue and productivity, as well as potential legal exposure or costs pertaining to recovering or remediating from an incident that endures for a longer time period.
- Enables Better Performance of Operational Tasks: Swift incident response processes, addressed by lower MTTRs, will enable valuable resources and personnel to address other tasks. Allowing the team to work on strategic initiatives, innovations, and proactive versus reactive responses during incident management.
- Improves Competitive Positioning: Companies that are known for being fast to recover and have high availability can gain a competitive advantage. If clients know they can rely on you, they will be compelled to trust you more and have confidence in your product or service.
Continuous MTTR optimization is a crucial component of cybersecurity risk management, enabling you to prevent damaging incidents, supplement security measures as they arise, and ultimately trust your digital infrastructure to avoid potential crises.
A Glimpse into Incident Response Dynamics
It is essential to understand the relationship between various incident response metrics to develop a comprehensive security model. The radar chart below depicts hypothetical performance across key incident response characteristics for three different organizations, detailing areas of strength and areas for improvement. The performance metrics are plotted on a scale of 1 to 5, with 5 being ahead of the curve.

The radar chart shows how different organizations prioritize or excel in various areas of incident management. For example, Organization C was strong across most incident response details, indicating it has a mature incident response program. Visualizations like this are helpful in identifying specific areas for improvement.
The Business Impact of MTTR Reduction
Beyond the technical aspects, the reduction of MTTR has tangible business impacts that directly affect an organization’s financial health and market standing. The following bar chart quantifies the hypothetical benefits of reducing MTTR across several key business metrics, on a scale of 0 to 10, with 10 being the highest benefit.
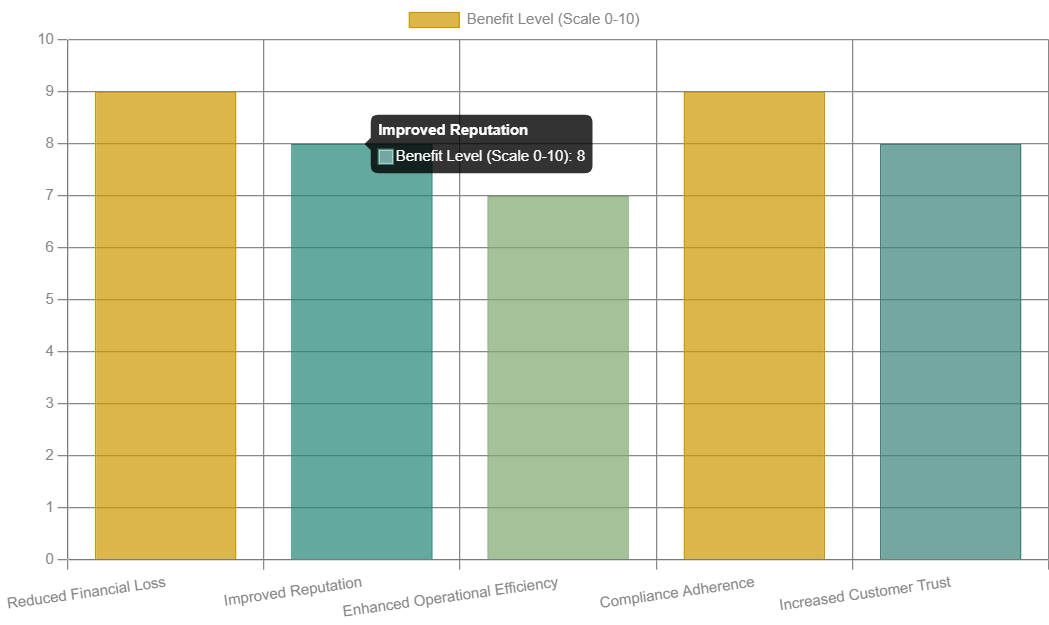
The bar graph shows that the real-world returns on investment gained by optimizing MTTR were huge. Strong scores in “Reduced Financial Loss” and “Compliance Adherence” show the direct positive impact on the organization financially and legally, and reinforce the strategic importance of this metric.
Understanding Key Incident Metrics: A Comparative Table
To further clarify the distinctions and relationships between various incident-related metrics, the following table provides a concise comparison, illustrating their primary focus areas and how they contribute to a comprehensive understanding of incident management effectiveness.
| Metric | Definition | Primary Focus Area | Relationship to MTTR |
| Mean Time to Detect (MTTD) | Average time from incident occurrence to detection. | Incident awareness and monitoring. | A low MTTD is a prerequisite for a low MTTR. An undetected incident cannot be resolved. |
| Response Time | Time from incident detection to the initiation of the first response action. | Initial mitigation and containment. | Often the initial phase of MTTR, influencing the overall resolution speed. |
| Mean Time to Repair/Resolve (MTTR) | Average time to fully repair, respond to, recover from, and resolve the root cause of an incident. | Comprehensive resolution and system restoration. | Encapsulates the entire process from detection through full recovery. |
| Recovery Time | Time taken to fully restore system functionality after an incident. | System restoration and service availability. | Often, the initial phase of MTTR influences the overall resolution speed. |
Conclusion: The Strategic Value of Rapid Response
Mean Time to Repair (MTTR) is a critical metric for all cybersecurity and IT professionals, as it relates to how effectively an organization detects, responds to, and recovers from incidents.
By investigating what MTTR means, understanding its value, and actively reducing MTTR, an organization can substantially enhance its cybersecurity posture and operational resilience. Utilizing new cybersecurity tools, such as AI-based monitoring, automation, and observability tools, is crucial to achieving this goal.
Given the scale and sophistication of cyber threats continue to grow, optimizing MTTR has become vital to the organization’s incident management processes. MTTR is an operational matter, but its impact on organizations can have financial, reputational, and long-term sustainability implications.
Professionals and students must ensure they are familiar with MTTR principles to help address the ongoing challenge of securing and maintaining trustworthy digital ecosystems.


